Introduction
On April 24, the AI technology community was abuzz with the launch of upgraded large models.
Just hours after OpenAI released its latest version, the Chinese large model DeepSeek announced the launch of its preview version, DeepSeek-V4, which is also open-sourced.
The official release includes a comprehensive 58-page technical report, marking a significant advancement in the efficiency and capability of large models in handling long texts.

Open Source Links

Dual Model Release
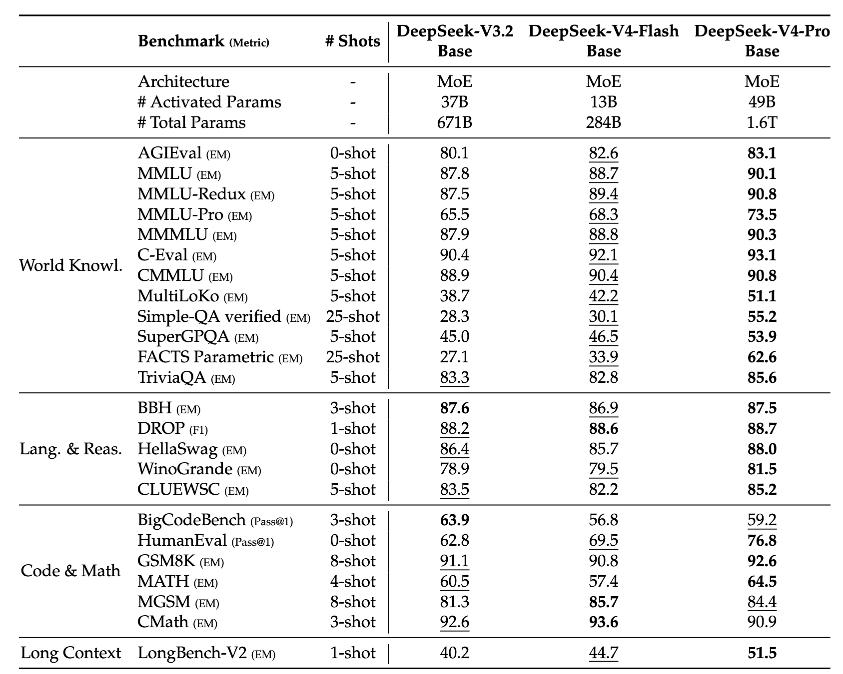
The DeepSeek-V4 series introduces two new models with MoE architecture, both supporting million-token context:
- DeepSeek-V4-Pro: 1.6 trillion total parameters, 49 billion active parameters, comparable to top closed-source models in knowledge, reasoning, code, and long document understanding.
- DeepSeek-V4-Flash: 284 billion total parameters, 13 billion active parameters, achieving near flagship reasoning performance with a minimal active parameter count.

Both models are reported to lead in agent capabilities, world knowledge, and reasoning performance within the domestic and open-source fields. Users can experience the latest DeepSeek-V4 capabilities directly on the DeepSeek website or app starting today.
Additionally, the API service has been updated; users can call the models by changing the model_name to deepseek-v4-pro or deepseek-v4-flash.

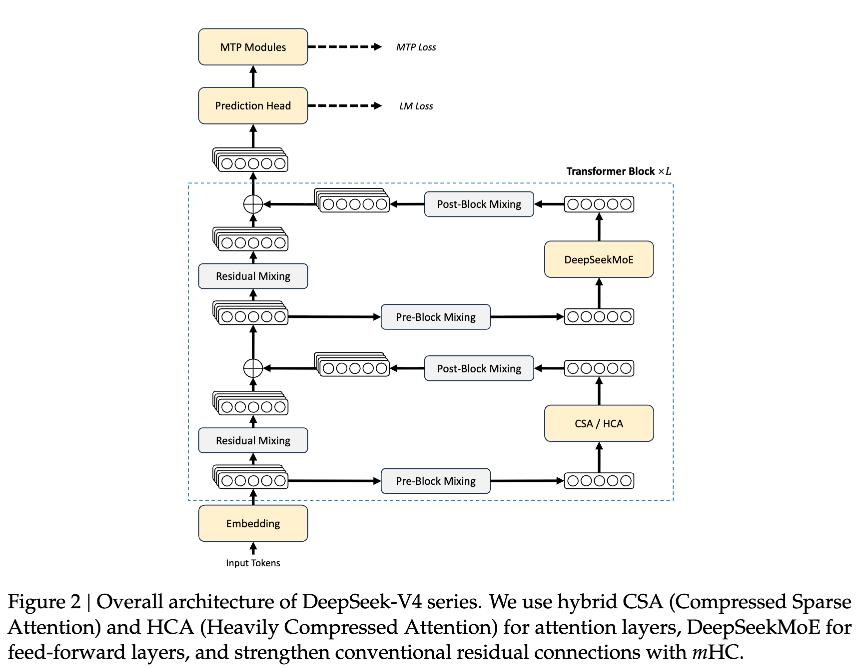
Architectural Upgrades and Key Innovations
From a technical architecture perspective, DeepSeek-V4 moves beyond traditional methods of simply stacking parameters and expanding data. It has undergone upgrades in three fundamental dimensions: attention mechanisms, residual connections, and optimizers.
In summary, compared to the DeepSeek-V3 architecture, the DeepSeek-V4 series retains the DeepSeekMoE framework and multi-token prediction (MTP) strategy while introducing several key innovations in architecture and optimization:
- A hybrid attention architecture combines compressed sparse attention (CSA) and heavy compressed attention (HCA) to enhance long context processing efficiency. CSA compresses key-value caches along the sequence dimension before executing DeepSeek sparse attention (DSA), while HCA applies more aggressive compression to key-value caches while maintaining dense attention.
- To enhance modeling capabilities, DeepSeek introduces manifold constraint hyperconnections (mHC) in the architecture, further improving information transfer capabilities based on traditional residual connections.
- The Muon optimizer has been integrated into the training of the DeepSeek-V4 series to accelerate convergence speed and improve training stability.
In training, DeepSeek pre-trained both models on over 32 trillion high-quality, diverse tokens and implemented a comprehensive post-training process to further enhance model capabilities.
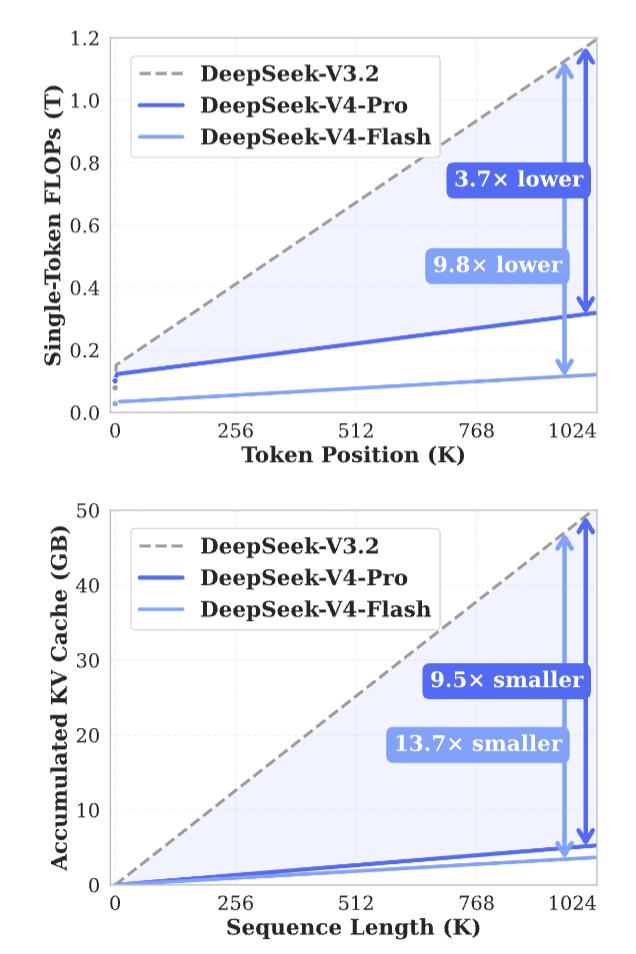
The technical report indicates that the DeepSeek-V4 series demonstrates high efficiency in long context scenarios. In a million-token context setting, DeepSeek-V4-Pro requires only 27% of the single-token inference FLOP of DeepSeek-V3.2, with KV cache usage at just 10%.
Consequently, DeepSeek can support “million-token context” as a standard capability, significantly enhancing the feasibility of long-sequence tasks and providing room for further expansion in testing phases. As stated officially, “From now on, a 1M (one million) context will be the standard for all official DeepSeek services.”

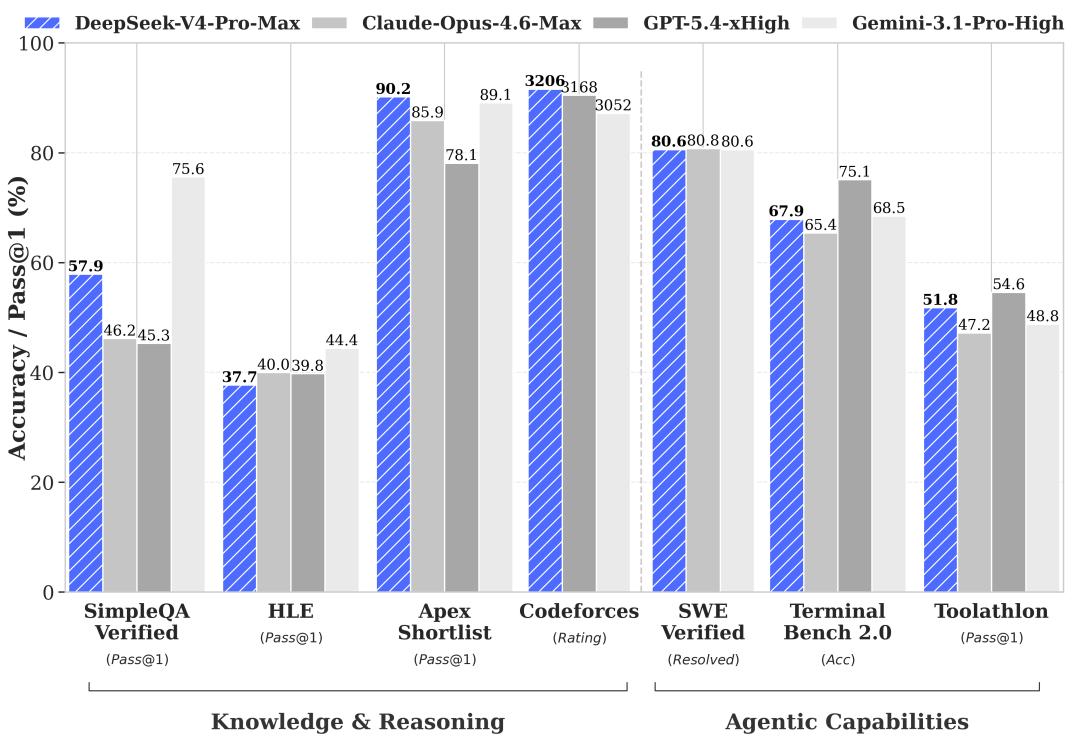
Performance Comparison
Notably, DeepSeek-V4-ProMax is the highest inference mode of DeepSeek-V4-Pro, redefining performance standards for open models and surpassing its predecessors in core tasks.
The performance of the DeepSeek-V4 series has seen significant improvements across multiple dimensions:
- In broad world knowledge assessments, DeepSeek-V4-Pro’s highest inference mode, DeepSeek-V4-Pro-Max, significantly outperforms mainstream open-source models in benchmarks such as SimpleQA and Chinese-SimpleQA.
In educational knowledge assessments (including MMLU-Pro, HLE, and GPQA), DeepSeek-V4-Pro-Max maintains a slight lead over open-source models. The gap between it and the leading closed-source model Gemini-3.1-Pro has narrowed considerably, although it still lags slightly in these knowledge tests.
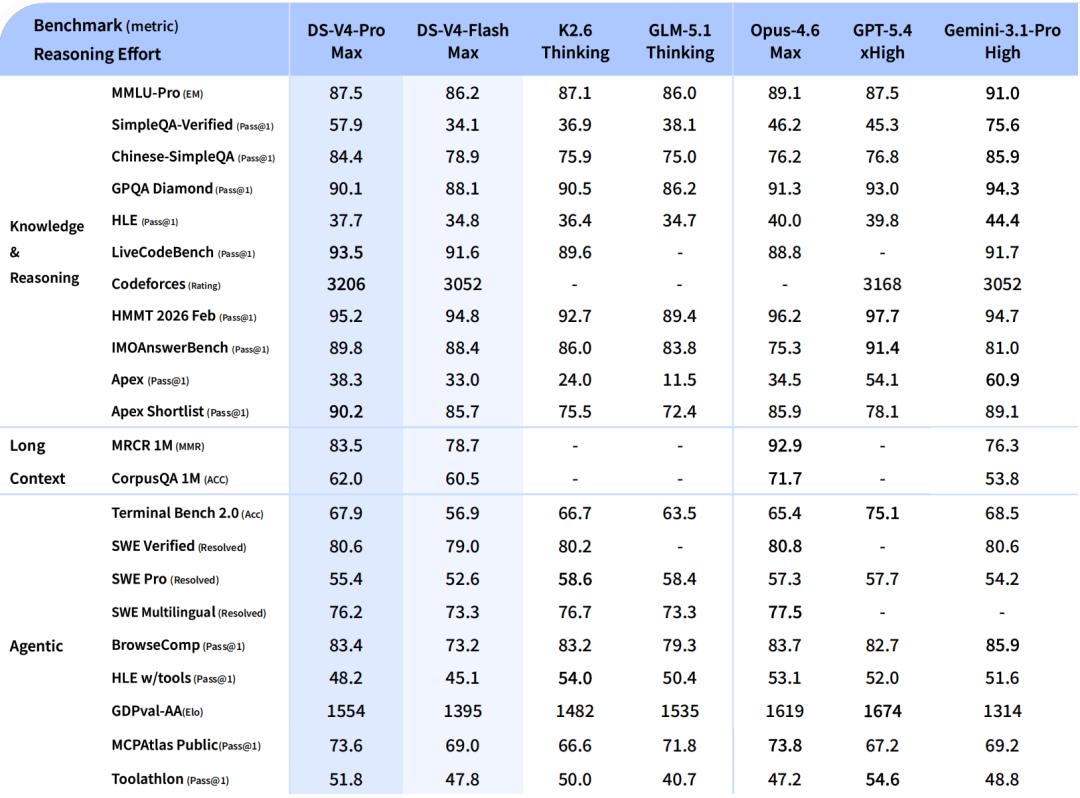
- In reasoning dimensions, by increasing the input of reasoning tokens, DeepSeek-V4-Pro-Max shows better performance than GPT-5.2 and Gemini-3.0-Pro on standard reasoning benchmarks.
However, its performance still falls slightly short of GPT-5.4 and Gemini-3.1-Pro, indicating that its overall development level is approximately 3 to 6 months behind the leading models.
Additionally, DeepSeek-V4-Flash-Max performs close to GPT-5.2 and Gemini-3.0-Pro in complex reasoning tasks, demonstrating high cost-effectiveness.
-
In agent capabilities, DeepSeek-V4-Pro-Max performs comparably to leading open-source models (such as Kimi-K2.6 and GLM-5.1) in public benchmark tests, but slightly lags behind top closed-source models. In internal evaluations, DeepSeek-V4-Pro-Max surpassed Claude Sonnet 4.5 and approached the level of Claude Opus 4.5.
-
With support for a million-token context window, DeepSeek-V4-Pro-Max excels in both synthetic tasks and real-world scenarios, even outperforming Gemini-3.1-Pro in academic benchmark tests.
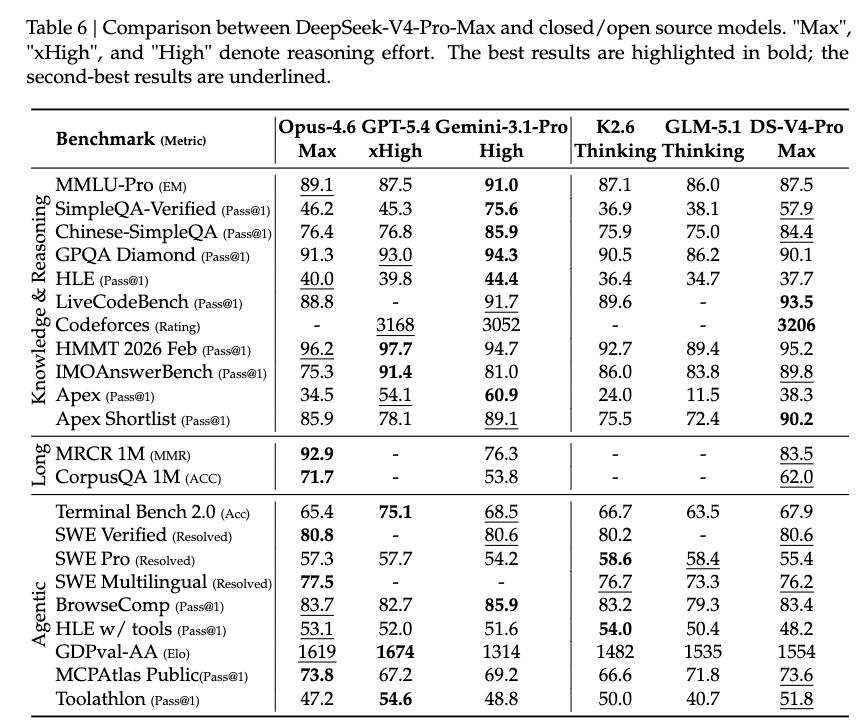
Compared to DeepSeek-V4-Pro-Max, DeepSeek-V4-Flash-Max shows slightly lower performance in knowledge assessments due to its smaller parameter size. However, when given a larger reasoning budget, its performance in reasoning tasks can approach that of DeepSeek-V4-Pro-Max.
In agent evaluations, DeepSeek-V4-Flash-Max can match DeepSeek-V4-Pro-Max on some benchmarks but still shows gaps in more complex and challenging tasks.

Computational Support
It is noteworthy that regarding the industry’s focus on domestic computational implementation, DeepSeek’s technical report indicates that they have validated their fine-grained EP (Expert Parallelism) solution on NVIDIA GPUs and Huawei Ascend NPUs.
Additionally, Huawei’s Ascend supernode series products have announced full support, achieved through close collaboration with chip technology to support the entire series of DeepSeek V4 models.


API Availability
The DeepSeek-V4 API is now live, supporting OpenAI ChatCompletions and Anthropic interface specifications.
When accessing the new models, the base_url remains unchanged, but the model parameter needs to be changed to deepseek-v4-pro or deepseek-v4-flash.
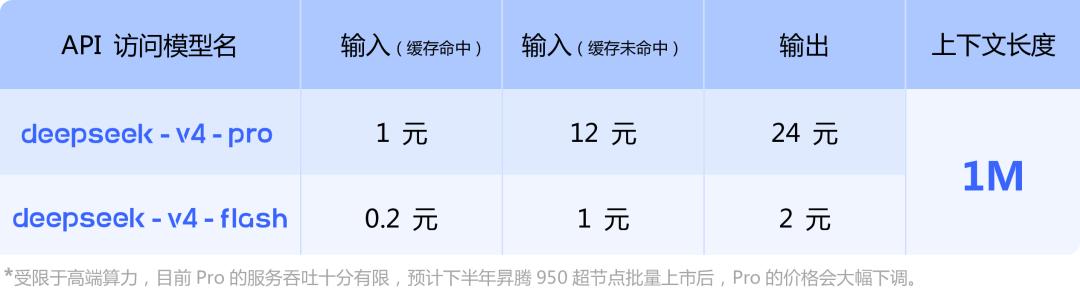
Furthermore, DeepSeek has announced that the old API model names deepseek-chat and deepseek-reasoner will be deprecated in three months (by July 24, 2026). Currently, these model names point to the non-reasoning and reasoning modes of deepseek-v4-flash, respectively.
Users can directly log in to the DeepSeek website or official app to experience the powerful capabilities brought by the million-token context: upload an entire book, project code, or contract document at once, achieving true “one-time understanding, full memory, and deep reasoning.”
The arrival of DeepSeek-V4 is not just a model upgrade; it signifies the entry of open-source large models into the “efficient era of million-token context.” It demonstrates through architectural innovation that ultra-long contexts do not require brute-force computing power, and small active parameters can achieve top-level reasoning.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.